

RAG: Retrieval-Augmented Generation - Da Teoria à Prática Empresarial Confiável
Introdução: A Revolução Tática na IA
Imagine o desafio clássico dos Modelos de Linguagem Grandes (LLMs): você tem um sistema que é um gênio articulado, com vasto conhecimento de mundo até a data de corte do seu treino. Ele é brilhante para linguagem e padrões. O problema? Sua memória é estática e não totalmente confiável em fatos específicos.
Ele pode "alucinar" — inventar detalhes que parecem plausíveis, mas são factualmente incorretos.
Para nós, que precisamos implementar soluções de IA em cenários de negócio onde a precisão e a governabilidade são críticas, a alucinação não é um inconveniente. É um blocker.

A Arquitetura RAG: Quando a Busca Otimiza a Geração
A solução para esse blocker é o Retrieval-Augmented Generation (RAG). É uma arquitetura que combina o poder de geração de linguagem do LLM (o Generator) com a precisão de um motor de busca de alta performance (o Retriever).
Vamos manter a analogia que funciona perfeitamente:
•Léo (O Generator): É o LLM. Genial na escrita e na contextualização, mas depende da sua memória interna (e às vezes falha).
•Ana (O Retriever): É o motor de busca vetorial. Não escreve, mas é impecável em encontrar o dado exato e atualizado em uma base de conhecimento externa.
Quando uma pergunta é feita, a Ana (Retriever) primeiro varre a base de dados (ex: seus documentos internos, a legislação mais recente, o manual técnico atualizado) e encontra os trechos relevantes. Ela entrega esses "fatos" para o Léo (Generator).
Agora, o Léo não precisa "lembrar" da informação. Ele é instruído a gerar a resposta baseando-se estritamente nos fatos que a Ana acabou de lhe entregar.
A resposta final não é apenas bem escrita; ela é factualmente correta, auditável e fundamentada na sua base de conhecimento proprietária e atualizada.
Os Pilares Fundamentais do RAG
1. A Decisão Estratégica: RAG vs. Fine-Tuning
Esta é a principal decisão de arquitetura, com implicações diretas em TCO (Custo Total de Propriedade), agilidade e manutenção.
Fine-Tuning: Altera os pesos do modelo. É como reformar a fundação do prédio. É caro (exige datasets massivos e alto poder de GPU), lento e cria um problema de "catastrophic forgetting". É útil para ensinar comportamentos e estilos, mas não para adicionar fatos voláteis.
RAG: Conecta uma fonte de dados externa. É como mobiliar o prédio. A "inteligência" (o LLM) é separada do "conhecimento" (o Vector Store).
O RAG é a escolha óbvia para cenários onde a verdade é volátil (leis, políticas internas, dados de mercado, manuais técnicos). Atualizar o conhecimento é uma simples operação de escrita no banco de vetores. O custo de retreinar um modelo a cada nova portaria ou atualização de produto seria proibitivo; com RAG, é trivial.

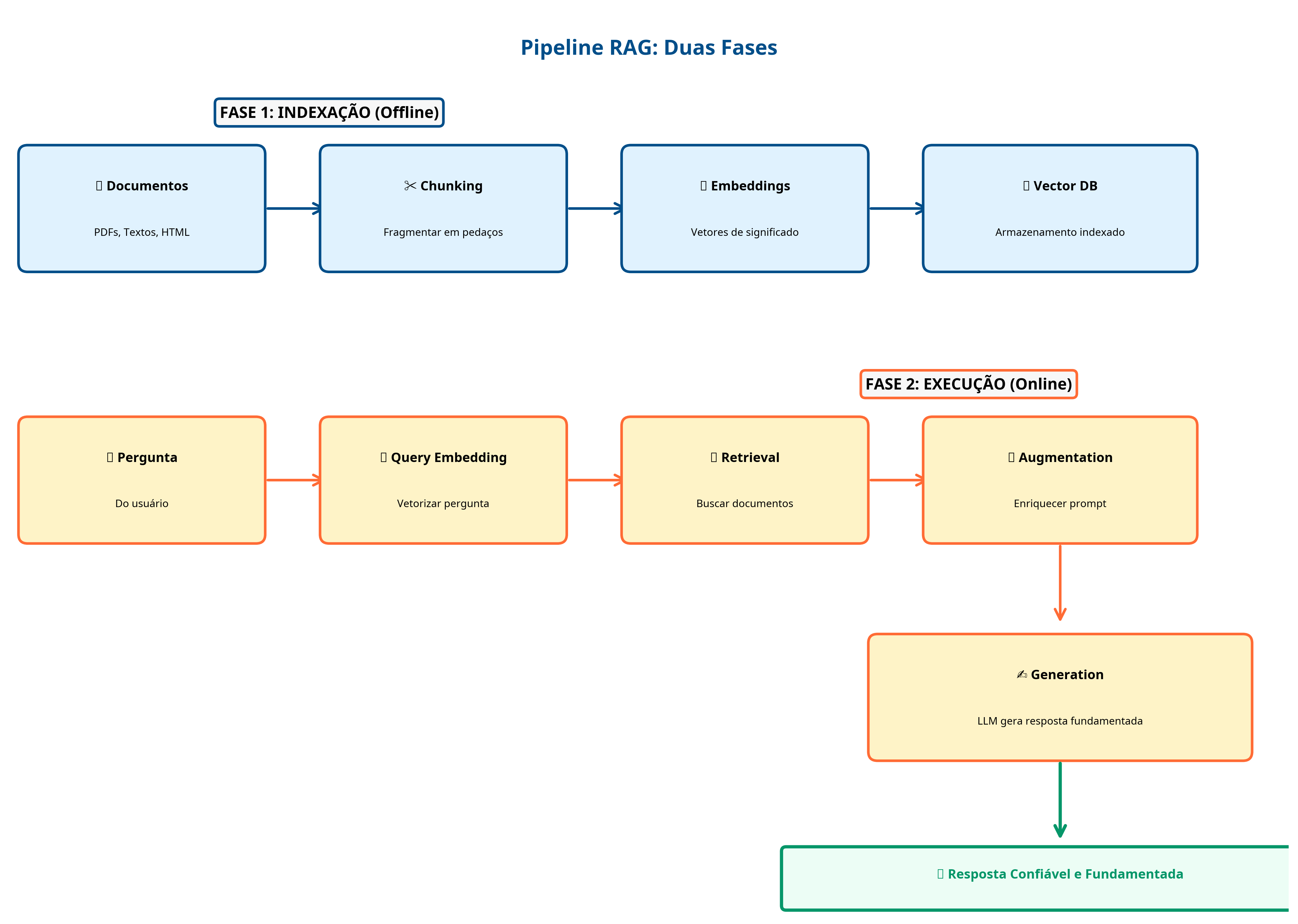
2. Decodificando a Arquitetura: O Pipeline
Tecnicamente, o processo é dividido em duas fases:
Fase 1: Indexação (Offline - O Data Prep)
Isso acontece antes de qualquer consulta, preparando sua base de conhecimento:
1.Carregamento de Documentos: Ingestão de fontes brutas (PDFs, .txt, HTML, etc.).
2.Chunking (Fragmentação): Quebrar os documentos em pedaços menores (chunks). A definição do chunk_size e chunk_overlap é crítica para manter o contexto semântico sem sobrecarregar o modelo.
3.Criação de Embeddings: Esta é a etapa central. Um modelo de embedding (um "mapa de significados") converte cada chunk de texto em um vetor numérico que representa seu significado semântico.
4.Armazenamento em Vector Database: Esses vetores são armazenados e indexados em um banco de dados vetorial (Vector Store). Esta é a "biblioteca" que a Ana (o Retriever) usará.
Fase 2: Execução (Online - O Pipeline de Resposta)
Isso acontece em tempo real a cada consulta do usuário:
1.Transformação da Query: A pergunta do usuário passa pelo mesmo modelo de embedding, tornando-se um vetor.
2.Recuperação (Retrieval): O Vector Store realiza uma busca de similaridade (ex: cosseno) para encontrar os chunks de documentos cujos vetores são mais próximos ao vetor da pergunta. A busca é por significado, não por palavra-chave.
3.Aumento (Augmentation): Os chunks recuperados (o "contexto") são formatados e inseridos no prompt junto com a pergunta original.
4.Geração (Generation): O LLM (Léo) recebe esse prompt enriquecido e gera a resposta final, com a instrução de se basear nos fatos fornecidos.
O Impacto Transformador do RAG
Para Negócios e Empresas
O RAG é o que torna os LLMs ferramentas de missão crítica.
Custo e Escalabilidade: Mantém-se um modelo base (que é mais barato) e o conhecimento factual é adicionado sob demanda no Vector Store, de forma incremental.
Confiabilidade e Auditoria: As respostas são fundamentadas em documentos específicos. O sistema pode (e deve) ser configurado para citar suas fontes (os chunks recuperados), fornecendo rastreabilidade e governabilidade.
Para E-commerce: Um Caso de Uso Prático
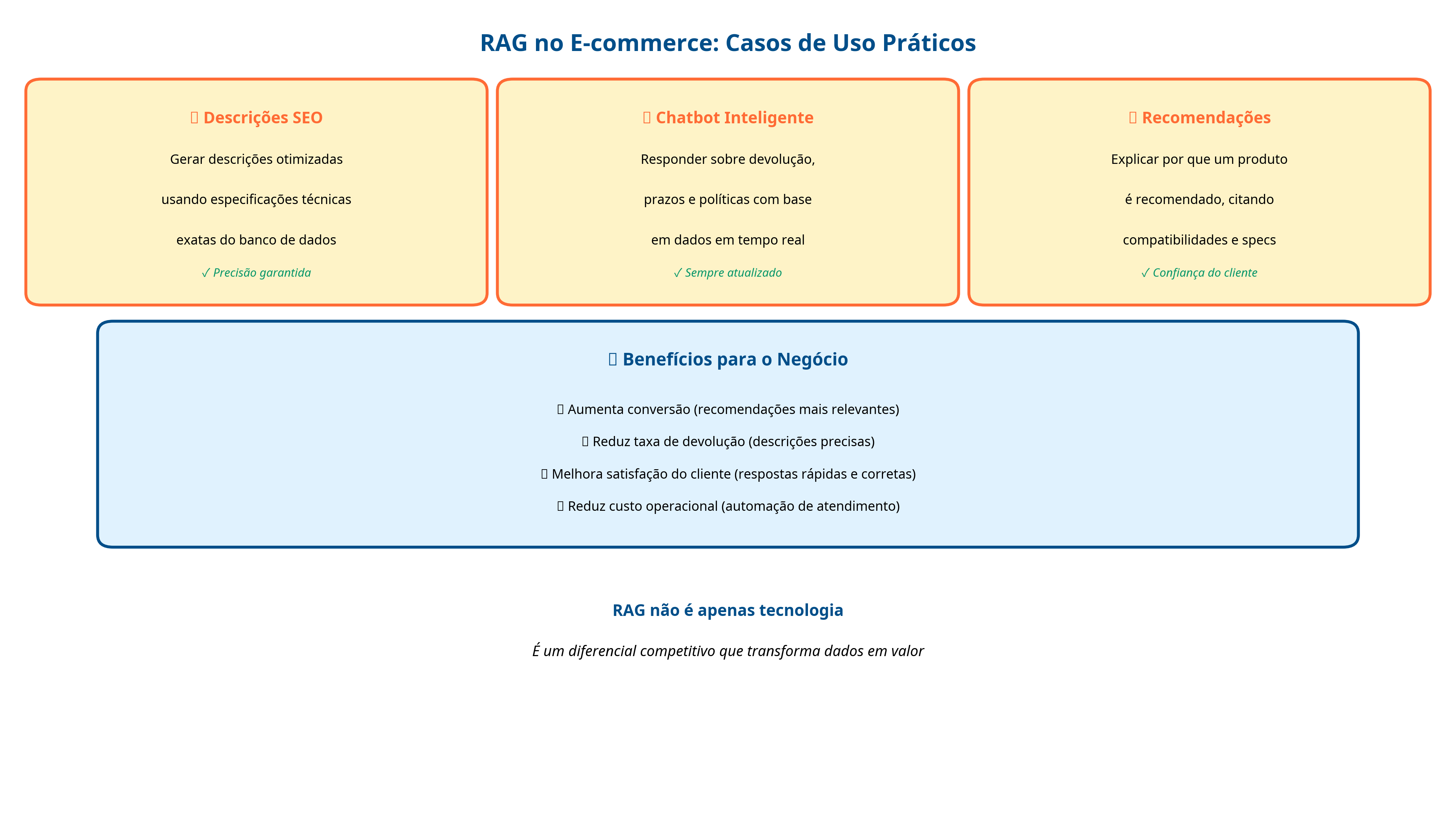
Descrições de Produtos: Geração de descrições otimizadas para SEO, usando especificações técnicas exatas recuperadas da base de dados do produto.
Atendimento ao Cliente: Chatbots que respondem sobre políticas de devolução ou prazos de entrega com base nas informações em tempo real do sistema, não em dados de treino desatualizados.
Recomendações Fundamentadas: O sistema pode explicar por que está recomendando um produto, citando compatibilidades ou especificações recuperadas.
Conclusão: O Futuro da IA Confiável
O RAG é um ponto de inflexão arquitetônico. Ele prova que um modelo de IA não precisa "saber" tudo em sua memória interna. Ele precisa ser excelente em interpretar, raciocinar e escrever, enquanto delega a tarefa de "lembrar" (o conhecimento factual) a mecanismos externos que são mais baratos, rápidos, atualizáveis e confiáveis.
A colaboração entre o Retriever (Ana) e o Generator (Léo) é o futuro da IA empresarial: sistemas que produzem respostas inteligentes, confiáveis, auditáveis e atualizadas.
Para empresas que buscam implementar IA de forma responsável e escalável, o RAG não é apenas uma opção técnica. É a resposta.
Referências
[1] Macedo, S. (2025). RAG - Retrieval-Augmented Generation: Para Leigos. Instituto Federal de Goiás. https://physia.com.br/rag/
[2] Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks". arXiv preprint arXiv:2005.11401. Disponível em: https://arxiv.org/abs/2005.11401
Observação: Este artigo foi gerado com auxílio de IA Generativa.






