


Do Excel ao Banco H2: Um Pipeline ETL Modular com Python e Java
- #Java
- #Modularização
- #Data
- #Python
Lições Aprendidas no Desenvolvimento de um Pipeline ETL com Python
Durante o desenvolvimento deste projeto, percorri uma jornada repleta de desafios técnicos, descobertas e aprendizados significativos. Ao optar por construir um pipeline ETL modular em Python, deixei para trás a familiaridade das planilhas e me comprometi com uma abordagem mais robusta, escalável e alinhada às boas práticas de engenharia de dados.
Este artigo reúne os principais aprendizados obtidos ao longo do processo, tanto em termos técnicos quanto em reflexões sobre a prática profissional.
Entendimento Profundo dos Dados
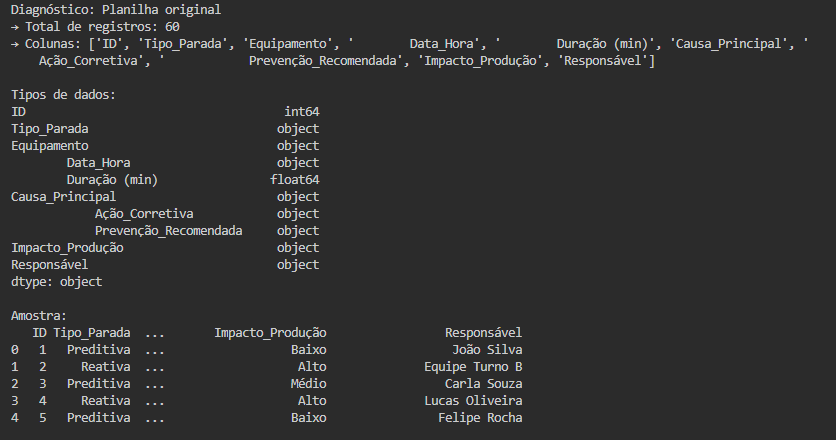
Logo nos primeiros passos, percebi que a estrutura da planilha fonte exigia uma análise cuidadosa: colunas com espaços e caracteres especiais, dados inconsistentes e formatos variados representavam obstáculos à automação confiável. Essa constatação me levou a desenvolver um módulo de transformação capaz de não apenas limpar os dados, mas também padronizá-los — passo fundamental para garantir a integridade e a consistência do pipeline.
A Importância da Padronização
A implementação da função padronizar_colunas representou um divisor de águas. Aprendi que remover acentos, espaços e caracteres especiais das colunas não é apenas uma questão de estilo ou estética, mas uma prática essencial para evitar erros na persistência dos dados em bancos relacionais. Esse tipo de padronização reduz significativamente a chance de falhas em etapas posteriores e contribui para a uniformização dos dados em ambientes distintos.
Testes e Auditoria como Ferramentas de Confiabilidade
A criação de arquivos de auditoria para registros rejeitados se mostrou extremamente valiosa. Essa abordagem permitiu manter rastreabilidade total sobre os dados processados e facilitou a identificação de problemas específicos ao longo do pipeline. Além disso, essa estratégia reforçou a confiabilidade do projeto e evidenciou a importância de tratar dados rejeitados com a mesma seriedade que os dados válidos.
Interoperabilidade entre Python e Java
Um dos aspectos mais enriquecedores do projeto foi a integração com o banco de dados H2, utilizando a biblioteca jaydebeapi. Essa experiência demonstrou, na prática, como é possível estabelecer uma comunicação eficaz entre Python e Java por meio da interface JDBC. Essa interoperabilidade me mostrou que o domínio de múltiplas linguagens pode ser um diferencial estratégico, especialmente em ambientes onde tecnologias distintas precisam coexistir.
Modularização e Reusabilidade
Ao estruturar o projeto em módulos independentes — extrair, transformar e persistir — obtive benefícios claros em termos de legibilidade, testabilidade e manutenção do código. Essa prática reforçou a importância de aplicar princípios de arquitetura também em projetos de dados, garantindo que cada componente possa evoluir de forma independente, sem comprometer a estabilidade do sistema como um todo.
Reflexão Final
Mais do que um exercício técnico, este projeto foi uma jornada de amadurecimento profissional. Reforcei minha confiança no Python como uma ferramenta essencial para a análise e a engenharia de dados, e percebi que cada desafio enfrentado representou uma oportunidade real de aprendizado. Sair da zona de conforto, explorar novas ferramentas e adotar boas práticas de desenvolvimento foram atitudes que tornaram o projeto não apenas funcional, mas também didático e escalável. Ao final desta jornada, sigo ainda mais motivado a enfrentar novos desafios, agora com um olhar mais crítico e uma base técnica mais sólida.
Do Excel ao Banco H2: Um Pipeline ETL Modular com Python e Java
Introdução
A confiabilidade dos dados é um dos pilares da análise de dados moderna. Planilhas Excel são amplamente utilizadas, mas apresentam limitações como risco de corrupção, dificuldade de versionamento e baixa escalabilidade. Este artigo apresenta um pipeline ETL modular desenvolvido em Python, com persistência em banco H2 via Java, como alternativa robusta e escalável para tratamento e armazenamento de dados industriais.
Arquitetura do Pipeline
O projeto foi dividido em módulos independentes, cada um com responsabilidade clara:
- extrair_excel.py: Responsável pela leitura da planilha.
- transformar_dados.py: Realiza limpeza, padronização e validação dos dados.
- banco_manager.py: Gerencia a persistência no banco H2 via JDBC.
- carregar_h2.py: Orquestra a execução do pipeline.
- diagnostico_utils.py: Realiza diagnósticos estruturais dos DataFrames.
Extração dos Dados
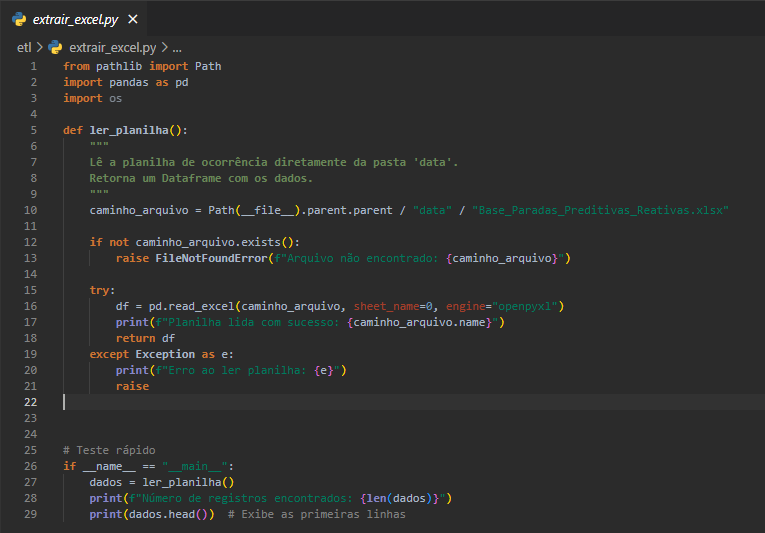
O módulo extrair_excel.py utiliza a biblioteca pandas com openpyxl para ler a planilha .xlsx diretamente da pasta data. Ele valida a existência do arquivo e retorna um DataFrame com os dados brutos.
Transformação e Limpeza
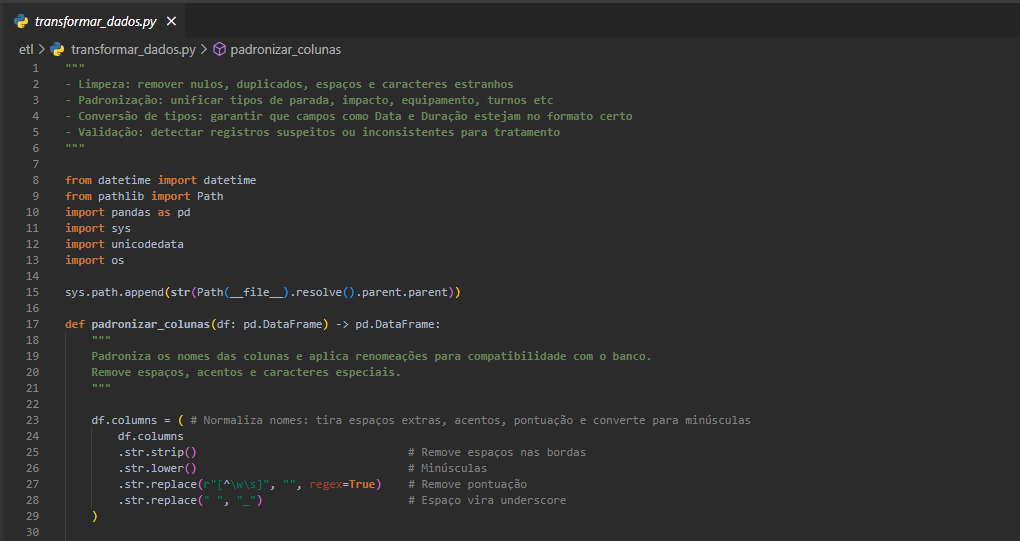
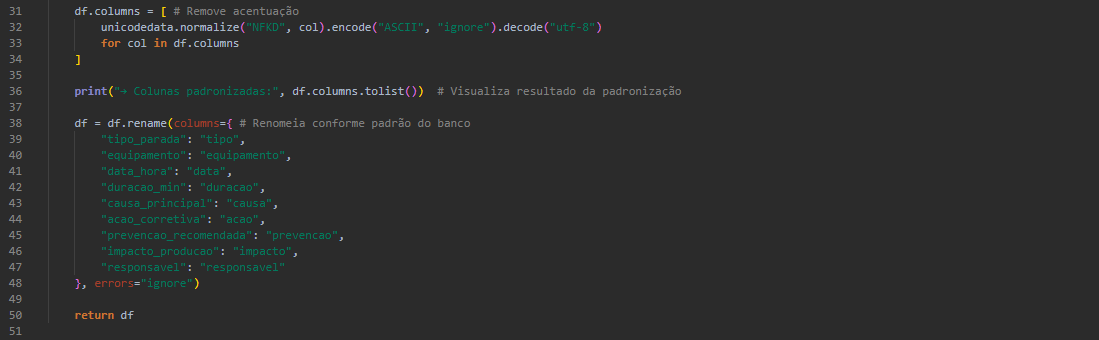
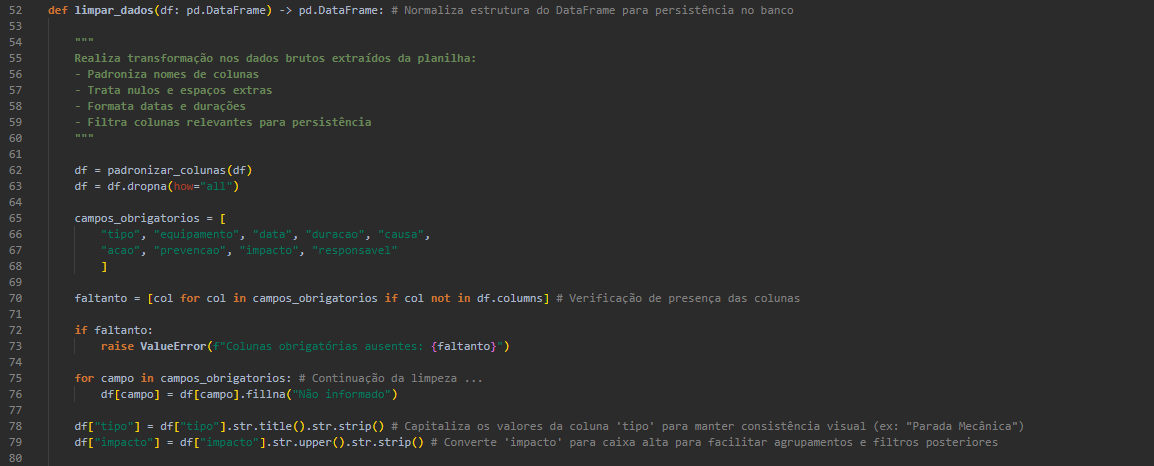
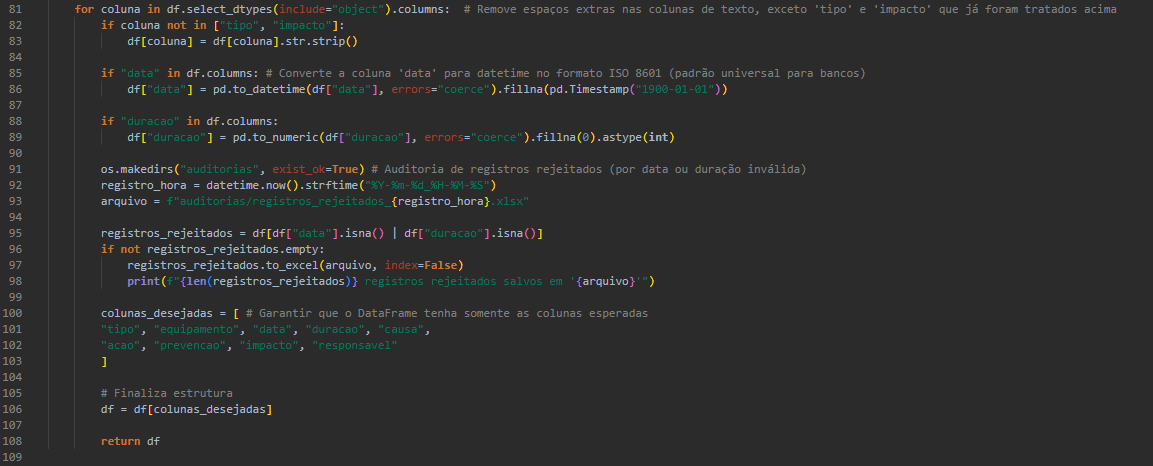
O módulo transformar_dados.py aplica uma série de transformações:
- Padronização de nomes de colunas (sem acentos, espaços ou caracteres especiais).
- Tratamento de valores nulos e normalização de texto.
- Conversão de datas e duração para formatos apropriados.
- Auditoria de registros rejeitados com exportação para Excel.
Persistência com H2 via Java
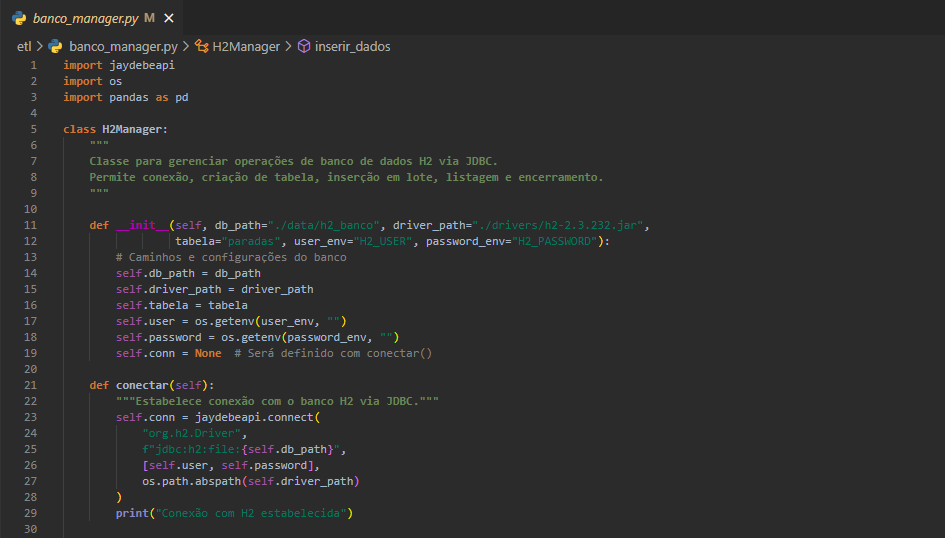
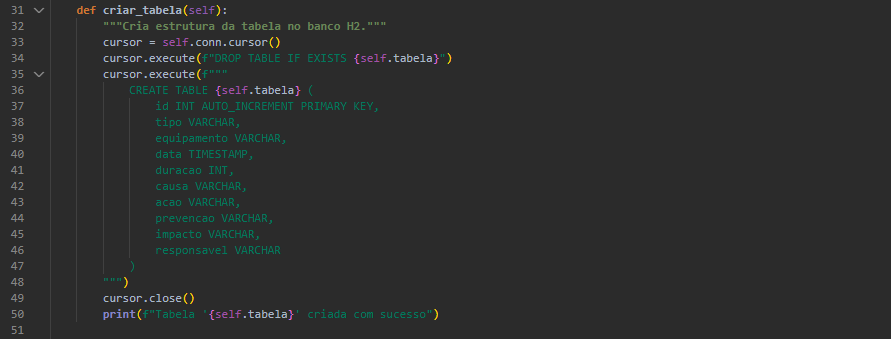
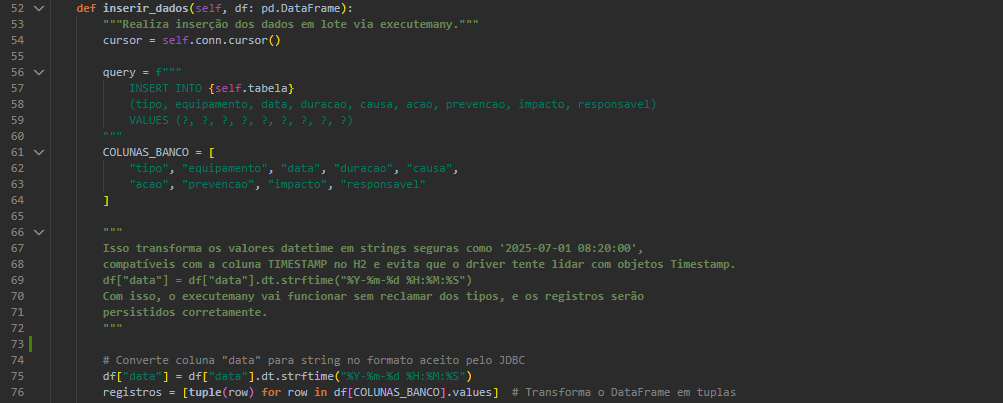
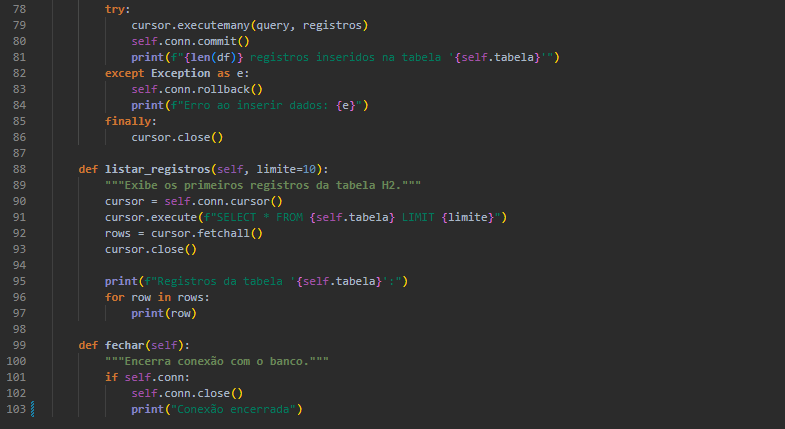
O módulo banco_manager.py utiliza jaydebeapi para conectar-se ao banco H2 via JDBC. Ele:
- Cria a estrutura da tabela com tipos apropriados.
- Converte datas para o formato YYYY-MM-DD HH:MM:SS.
- Realiza inserção em lote com executemany.
- Permite listar registros e encerrar a conexão.
Execução do Pipeline
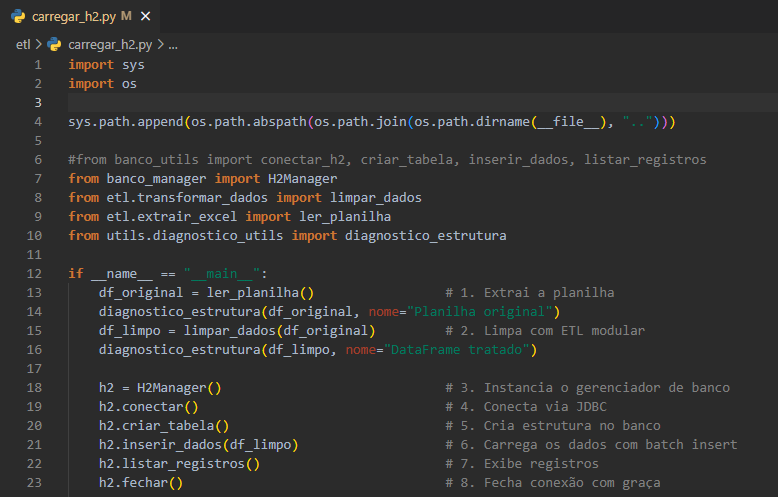
O script carregar_h2.py orquestra todo o processo:
- Extrai os dados da planilha.
- Aplica a transformação e limpeza.
- Conecta ao banco H2.
- Cria a tabela e insere os dados.
- Lista os registros inseridos.
- Encerra a conexão com o banco.
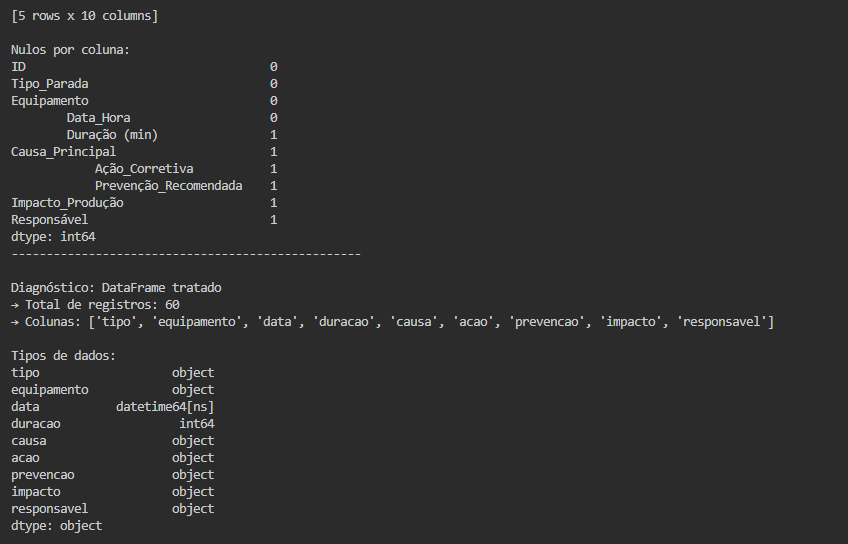
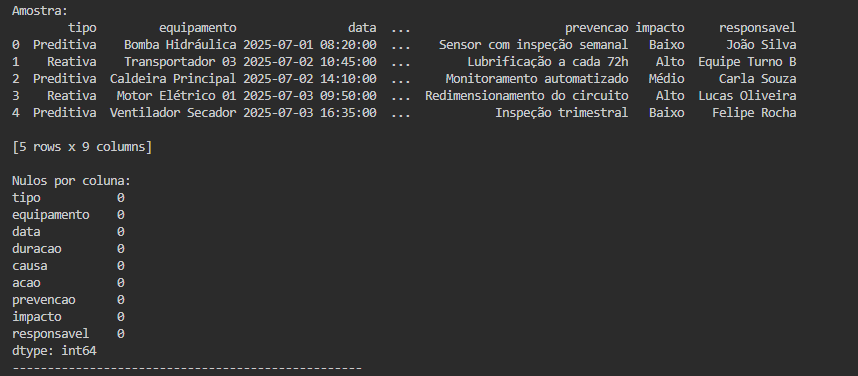
Terminal

H2 Console
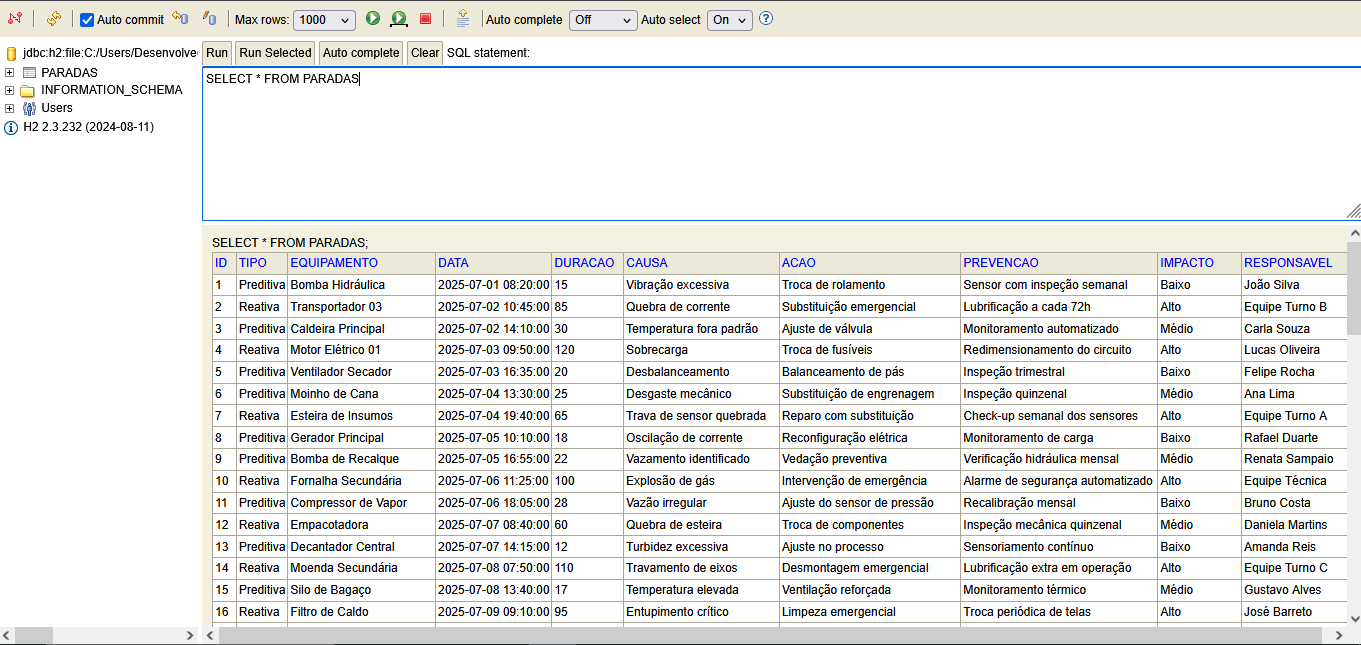
Conclusão
Este projeto demonstra como o Python pode ser utilizado para construir pipelines ETL modulares, robustos e reutilizáveis. A integração com o banco H2 via Java oferece uma alternativa confiável à manipulação direta de planilhas, promovendo escalabilidade e segurança dos dados.
🔍 O que é ETL?
ETL é um acrônimo para Extract, Transform, Load (Extrair, Transformar e Carregar). É um processo essencial em projetos de dados que consiste em:
- Extrair dados de fontes diversas (planilhas, bancos, APIs).
- Transformar os dados para corrigir, padronizar e preparar para análise.
- Carregar os dados tratados em um sistema de armazenamento confiável, como bancos de dados.
No projeto apresentado, o ETL foi implementado de forma modular com Python, garantindo clareza, reusabilidade e robustez.
🧰 Bibliotecas Python Utilizadas
Durante o desenvolvimento do pipeline, foram utilizadas as seguintes bibliotecas:
- pandas: Manipulação de dados tabulares.
- openpyxl: Leitura de arquivos Excel .xlsx
- jaydebeapi: Conexão com banco de dados H2 via JDBC.
- unicodedata: Normalização de acentuação.
- os: Interação com o sistema operacional.
- pathlib: Manipulação de caminhos e arquivos.
- datetime: Tratamento de datas e horários.







PH
Artigo excelente! Demonstra de forma clara e prática como criar um pipeline ETL eficiente com Python e Java.
Excelente, Vinicius! Que artigo incrível sobre Do Excel ao Banco H2: Um Pipeline ETL Modular com Python e Java! É fascinante ver como você transformou o desafio de um projeto em uma jornada de aprendizados significativos, construindo um pipeline ETL modular e robusto.
Você demonstrou a importância de padronizar os dados, a valia de testes e auditoria para confiabilidade e a riqueza da interoperabilidade entre Python e Java com jaydebeapi. Sua análise da modularização e reusabilidade do código inspira a enfrentar novos desafios com um olhar mais crítico e uma base técnica sólida.
Considerando que "a implementação da função padronizar_colunas representou um divisor de águas" para evitar erros na persistência dos dados em bancos relacionais, qual você diria que é o maior benefício para um profissional de dados ao investir tempo na padronização de dados, em termos de integridade e consistência do pipeline, mesmo que a princípio pareça um detalhe?