

Gradiente Descendente - Uma fácil explicação.
- #Python
- #Machine Learning
Vamos imaginar o seguinte cenário: estamos discutindo um algoritmo genérico que busca a solução ótima minimizando uma função de custo. Eu te proponho o seguinte: imagine estar perdido em um lugar como uma montanha. A melhor maneira de determinar se estamos encontrando a base da montanha é olhar para baixo e caminhar nessa direção.
Isso é basicamente o que o gradiente descendente faz: a função tenta encontrar o valor mínimo do erro em relação ao vetor parâmetro θ, esse parâmetro é muito utilizado em regressão linear (isso nos ajudará a saber o quanto estamos longe ou próximos do resultado esperado). Aliás, essa função tipicamente não tem um valor inicial atribuído. Em vez disso, um valor aleatório é frequentemente escolhido, pois assim conseguimos evitar, por exemplo, achar o mínimo local que não seja o mínimo global. Você pode ver um pouco mais sobre isso aqui.
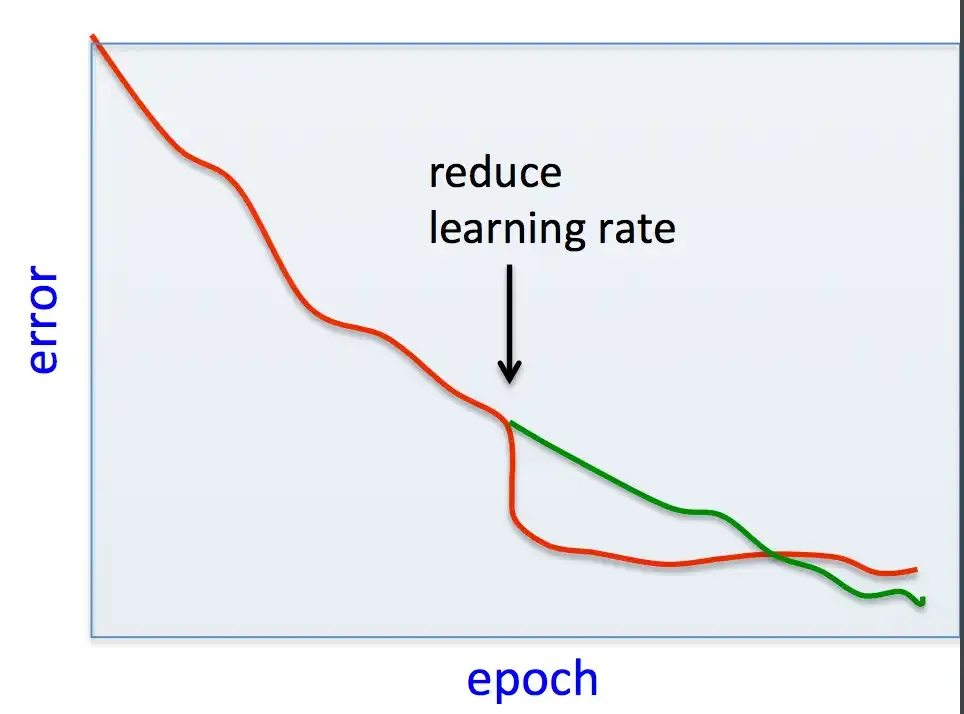
Outro ponto importante para considerarmos é a taxa de aprendizado (learning rate). Uma taxa de aprendizado (α) baixa exigirá mais iterações para o modelo convergir, enquanto uma taxa de aprendizado (α) alta pode impedir que ele encontre a solução ótima para o nosso problema. Por sua vez, um baixo aprendizado atrelado a poucas iterações pode nunca nos tirar do platô dessa função, fazendo com que a função tenha uma convergência prematura, e uma taxa de aprendizado alta pode fazer com que o modelo diverja, fazendo com que os valores aumentem mais e mais. Então, é bom termos um fine-tuning dos hiperparâmetros. Mas, como uma taxa de aprendizado alta impedirá de acharmos uma solução?
Aqui está uma analogia: imagine uma bola que nunca perde energia. Se você a soltar com uma força inicial pequena, ela quicará várias vezes antes de chegar no ponto ótimo onde ela irá parar automaticamente, representando a convergência gradual do algoritmo. No entanto, se você soltar/jogar a bola com muita força, ela pode quicar descontroladamente e nunca alcançar o ponto ótimo, similar a como uma taxa de aprendizado alta pode levar o algoritmo a perder a solução ótima. Mas isso não significa que uma taxa de aprendizado alta não trará a solução ótima; ela pode trazer, mas pode demorar bem mais.






