


O Custo Oculto da Força Bruta no Machine Learning
O problema do "chute de luxo"
No meu último artigo, provoquei sobre governança: quem garante que o modelo de IA que você usa hoje não está mentindo para você?
Mas existe um segundo problema — mais silencioso e muitas vezes mais caro: a ineficiência computacional.
Hoje, AutoML (Automated Machine Learning) tornou-se, na prática, sinônimo de força bruta.
Pegamos um dataset, jogamos contra 50 algoritmos diferentes e esperamos que a eletricidade e o tempo de CPU nos digam quem venceu.
É o equivalente a um médico que prescreve todos os remédios da farmácia e espera ver qual funciona primeiro.
Funciona? Às vezes.
É inteligente? Definitivamente não.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
O resgate: John R. Rice e a teoria de 1976
Pouca gente no dia a dia da ciência de dados cita John R. Rice, mas em 1976 ele formalizou o que hoje chamamos de Algorithm Selection Theory (AST).
A pergunta dele era simples — e brutal:
Como escolher o algoritmo certo antes mesmo de testar todos eles?
Rice propôs que cada problema possui um tipo de DNA computacional, definido por meta-features como:
- grau de desbalanceamento
- estrutura de correlação
- entropia dos dados
- dimensionalidade
- complexidade estatística
Se conseguirmos ler esse DNA, não precisamos testar tudo.
Podemos prever quais algoritmos têm maior probabilidade de sucesso.
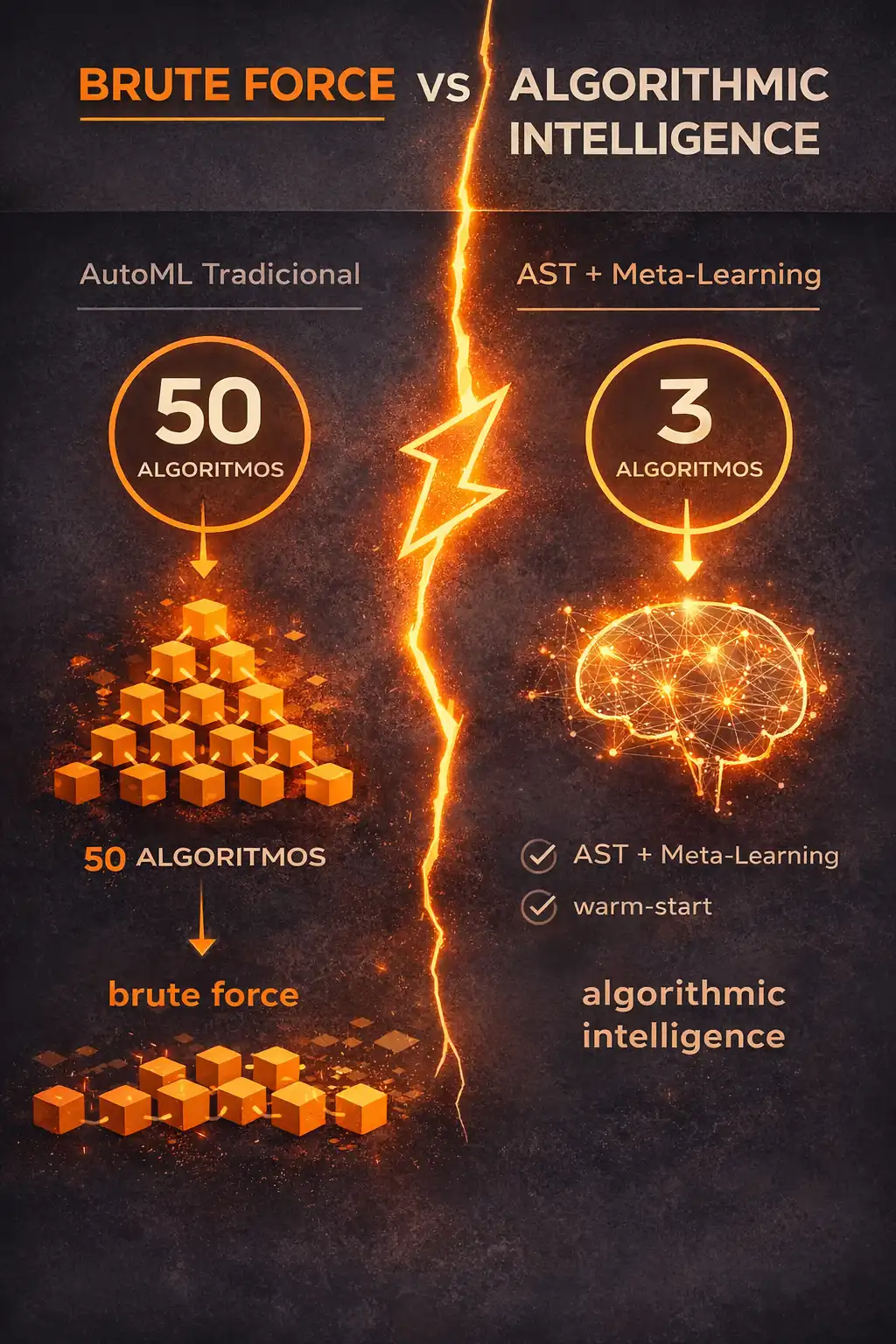
Comparativo do ML tradicional x proposta de ML usando Teoria de Seleção Algorítmica.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Onde estamos errando?
O mercado se acostumou com a ilusão do Cloud infinito.
Como o processamento parece barato (até a conta chegar no fim do mês), paramos de pensar algoritmicamente.
O resultado é previsível:
1️ Desperdício computacional
Horas de GPU são gastas em experimentos que poderiam ser descartados em segundos.
2️ Amnésia organizacional
Cada novo treinamento começa do zero, como se a empresa nunca tivesse visto um problema de churn, fraude ou crédito antes.
A ciência de dados virou um ciclo permanente de tentativa e erro computacional.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
O que é possível hoje?
A tecnologia atual permite algo muito mais inteligente.
Imagine um ecossistema onde o Machine Learning não é reativo, mas pró-ativo.
Um sistema que:
- extrai automaticamente o perfil estrutural de um dataset no momento do upload
- consulta um atlas de experiências anteriores
- correlaciona o DNA do problema com milhares de sucessos e falhas históricos
- recomenda a estratégia antes do primeiro treino
Nesse cenário, o AutoML deixa de ser força bruta.
Ele se torna engenharia científica guiada por experiência acumulada.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
A decisão
Diante desse cenário de desperdício e baixa integridade científica, cheguei a uma conclusão simples:
Não era mais possível apenas observar.
Nas últimas semanas tenho trabalhado obsessivamente em um projeto que conecta a teoria clássica de John Rice com a infraestrutura moderna de Machine Learning.
Uma arquitetura que tira o ML da era da tentativa e erro e o leva para a era das IAs pró-ativas e agênticas.
O objetivo é simples: eficiência máxima + custo mínimo + transparência total
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
O futuro do Machine Learning
O futuro do Machine Learning não está em testar mais algoritmos.
Está em saber antecipadamente quais valem a pena testar.
Eficiência científica será o único caminho sustentável para escalar IA com integridade.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
E você?
Sua operação de Machine Learning é guiada por ciência…
ou por força bruta computacional?




